Thinking
Ideveloper's

ideveloper
Sep 28, 2020 - 5 min read
redux 공식 문서 톺아보기 1

시작하기에 앞서
익숙한 듯 redux를 사용하긴 하지만, 선뜻 redux가 왜나오게 되었고, 어떠한 원리를 통해 동작하고, 어떠한 설계를 통해 구성 되어졌는지는 자신있게 얘기하지 못하고 있는것 같아, 공식문서를 한번 톺아보기로 했다. 또 이러한 글들을 읽어보며, 공식문서의 Thinking in Redux 몇몇 부분들을 발췌해 추가로 필요한 개념들을 정리해보았다.

redux 의 motivation
https://redux.js.org/understanding/thinking-in-redux/motivation#motivation 참고
변화(mutation)와 비동기성(asynchronocity)
일단 redux라는 라이브러리가 어떻게 나오게 되었는지 그 배경에 대해서 공식문서를 통해 알아보자.
우선, 이전에 비해 우리의 코드는 많은 상태를 관리해야만 했고, 이러한 상태라는 것은 서버의 응답과 캐시된 데이터, 서버에 종속적이지 않은 로컬상에 만들어진 데이터들을 포함한다고 공식문서는 설명하고 있다.
또한 특정한 모델이 다른 모델을 업데이트가 가능하게 하면, 즉 어떠한 뷰가 한 모델을 업데이트하고 또 그 모델이 다른 모델을 업데이트해 다른 뷰가 업데이트 하게 된다면 개발자는 상태를 언제, 어떻게 그리고 왜 업데이트 하는지에 대한 제어권을 잃어버리게 된다고 설명하였다.
그리고 프론트엔드에서의 복잡성은 두가지 개념을 함께 다룰때 발생하는 것이라 하였고,**변화(mutation)와 비동기성(asynchronocity)**이 그 두가지 요인이라고 소개했다. 둘이 엮이면 아주 복잡해지고 어려운 상황이 발생한다고 하여 그 둘을 멘토스와 콜라라고 비유하기도 했다.ㅎㅎ
이러한 복잡성 때문에, 리액트는 뷰 레이어에서의 이러한 문제를 풀려고 비동기성과 직접적인 DOM 조작을 제거하는등의 시도를 했다고 소개하고 있다. **그중 "리액트는 어떻게 비동기성을 제거했을까?"**가 궁금하여 검색을 해보았는데 이러한답변이 달려있었고 이는 아래와 같다.
It removes asynchronous behavior from the view layer by design. You must not do async stuff in render or what is rendered will be broken.
즉, 설계단에서 비동기적인 동작은 뷰레이어에서 하지않게 했고, render 메소드에서 비동기적인 어떠한 행동이든 할수 없게 만든것이다. 그러나 뷰레이어는 그렇다치고, 상태를 조작하는것은 우리에게 달려있고, 이러한 복잡해진 상태 관리 측면에서 redux가 나오게 되었다고 소개하고 있었다.
Flux, CQRS, Event Sourcing
또 Flux, CQRS, Event Sourcing의 단계들을 따라서, **몇가지 원칙(그 제한들은 우리가 잘 알고있는 redux의 세가지 원칙인것이다.)**등을 강제해 예측가능한 상태변화를 가능하게 했다고 하였다. 그러나 이러한 개념들이 어떻게 녹아들었는지는 의문이었다. flux는 개념을 이미 많이 접했지만 그외 다른것들(CQRS, Event Sourcing)은 프론트개발과 연관지었을때 생소한 개념이긴했고 이름정도만 들었기 때문이다.
redux에서의 CQRS를 알기 위해 아래 포스팅을 읽어보았다. CQRS와 이벤트 소싱의 개념은 아주 밀접한 관련이 있었는데 CQRS 시스템을 구현할때 모든 명령들은 event들로 모델링 되어있다고 한다. 또한 이러한 점때문에 event sourcing으로 불리기도 한다고 한다. https://medium.com/@swazza85/understanding-redux-as-a-cqrs-system-177526aa4671
(아래 그림을 보면 redux를 사용할때의 익숙한 개념들이 많이 등장한다.)
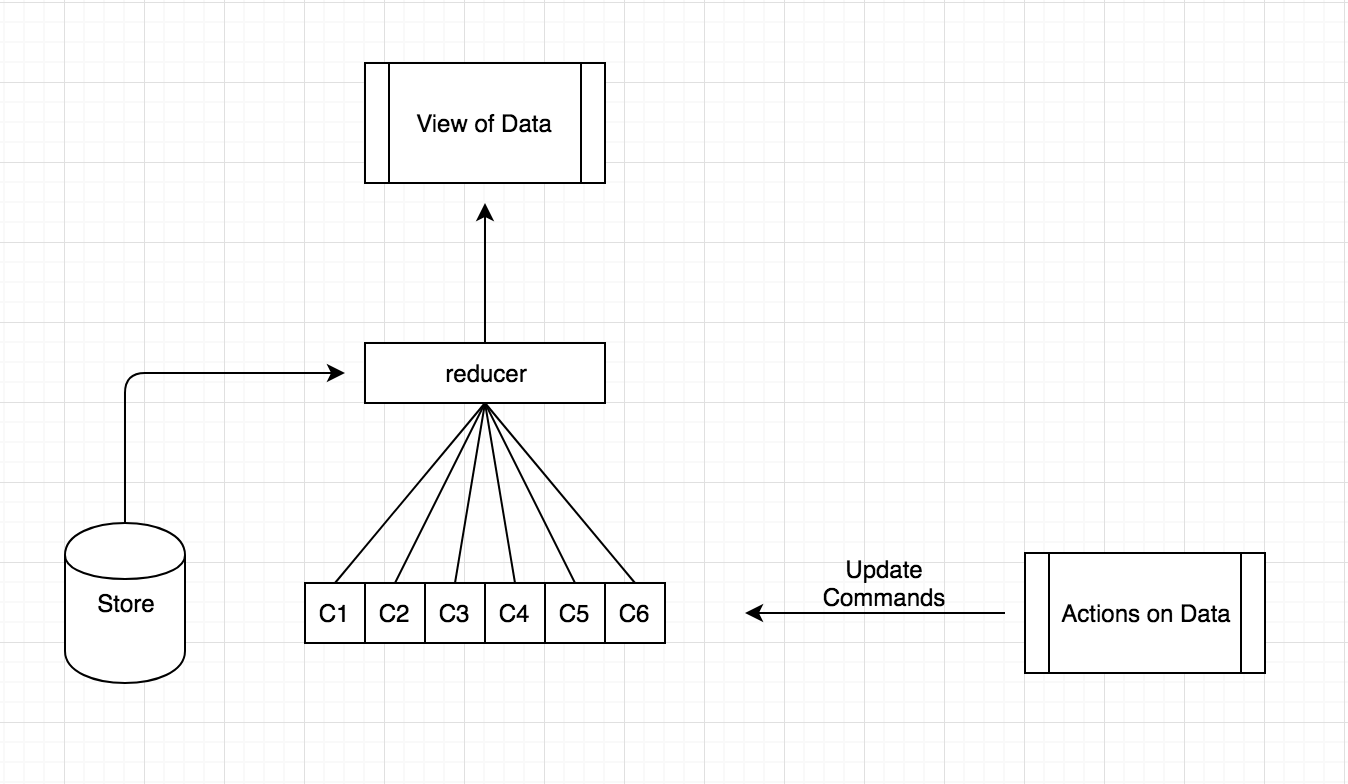
그리고 아래는 CQRS를 구현한 코드인데 redux 코드와 상당히 많은 부분이 닮아있었다. 위 첨부한 글에서도 counter 함수는 redux의 reducer와 유사한 성격을띄고, commands 배열은 모든 reducer의 배열들이 되는것이다.
let store = {
counter: 0,
};
const increment = { type: "INCREMENT" };
const decrement = { type: "DECREMENT" };
let counter = (state, action) => {
switch (action.type) {
case "INCREMENT":
return state + 1;
case "DECREMENT":
return state - 1;
}
};
let commands = [counter];
let dispatch = (action) => {
commands.reduce((intermediateStore, command) => {
let storeFragment = store[command.name];
store[command.name] = command(storeFragment, action);
return store;
}, store);
};
dispatch(increment);
dispatch(increment);
dispatch(decrement);
console.log(store);
// assert.equals(store.count, 1)
// try it out on the babel repl그렇다면 다시 돌아와서 이러한 개념들이 예측가능한 상태변화를 어떻게 만들었는지 생각해보았는데 위와 같이, 특정 액션을 디스패치하게되고, reducer에서 관련한 액션들을 처리해 상태를 업데이트 해주므로, 상태를 변화시키는 요인을 특정레이어에 모델 업데이트 로직을 집중시켜주게 해주어, 어떤 trigger로 인해 상태가 변화되었는지를 쉽게 체크할수 있도록 redux가 CQRS 개념등을 차용한것을 알 수 있었다.
Redux의 세가지 원칙
https://redux.js.org/understanding/thinking-in-redux/three-principles 참고
1.Single source of truth
많이들 알고 있는 global state는 하나의 store에만 존재해야 한다는 원칙이다. 이로인해 debug도 쉬워지고 빠른 개발이 가능해졌다고 한다.
2.State is read-only
상태를 바꾸는 방법은 state를 직접 건드리는게 아니라 오직 action을 emit하는것 뿐이라는 원칙이다. 또한 모든 변화들이 중앙집권화 되어있고, 엄격한 순서대로 진행되며 미묘한 다른 변경사항들을 볼 필요가 없어진것이다. 또한 action은 일반적인 object의 형태이므로 로깅될수 있고, serialize 될수 있고 저장되고 다시 디버깅이나 테스트를 위해 replay 시킬수도 있다고 한다. (당연하게 redux debugger로 보고있던것들을 다시한번 고찰하게되었다.)
3.Changes are made with pure functions
순수함수로 변화가 이뤄져야 한다는 것이다. 리듀서들은 이전 상태와 액션을 가지고 있고, 새로운 상태를 반환하게 된다. 우리는 리듀서가 순수함수여야 된다고 당연하게 말하고 있긴 하지만, 리듀서가 순수함수여야 하는 이유에 대해서 더 긴밀히 조사를 해보았다.
redux의 reducer가 순수함수여야하는 이유 더 조사
https://redux.js.org/faq/reducers#reducers
우선 순수함수는 동일한 인자가 주어졌을 때 항상 동일한 결과를 반환하는 것을 말하고, 함수 내의 변수 외에 외부의 값을 참조, 의존하거나 변경하지 않아야 한다. 이러한 순수함수의 성격과 reducer의 동작을 비교해 보면 좋은데 reducer를 구현할 때 인자로 들어온 state를 직접 수정하지 않고 복사본을 만들어 return해주는 이유는 redux의 변경 감지 알고리즘 때문이다. 이를 redux 내부 코드로 살펴보면 아래와 같다.
let hasChanged = false
const nextState: StateFromReducersMapObject<typeof reducers> = {}
for (let i = 0; i < finalReducerKeys.length; i++) {
const key = finalReducerKeys[i]
const reducer = finalReducers[key]
const previousStateForKey = state[key]
const nextStateForKey = reducer(previousStateForKey, action)
if (typeof nextStateForKey === 'undefined') {
const errorMessage = getUndefinedStateErrorMessage(key, action)
throw new Error(errorMessage)
}
nextState[key] = nextStateForKey
```
hasChanged = hasChanged || nextStateForKey !== previousStateForKey
```
}
hasChanged =
hasChanged || finalReducerKeys.length !== Object.keys(state).length
return hasChanged ? nextState : state
}https://github.com/reduxjs/redux/blob/master/src/combineReducers.ts#L203 를 보면 object를 단순히 주소(reference)값을 비교 하는것을 알 수 있다.
리덕스는 두 객체(prevState,newState)의 메모리 위치를 비교하여 이전 객체가 새 객체와 동일한지 여부를 단순 체크한다. 만약 리듀서 내부에서 이전 객체의 속성을 변경하면 새 상태 와 이전 상태가 같은 메모리 주소를 가지므로 모두 동일한 객체를 가리킨다. 그렇게 되면 리덕스는 아무것도 변경되지 않았다고 판단하여 동작하지 않는다.이러한 이유 때문에 리듀서는 순수함수의 성격을 띠게 된것이다.
그렇다면 redux는 왜 이렇게 간단히만 비교를 할까?
https://redux.js.org/faq/immutable-data#why-does-reduxs-use-of-shallow-equality-checking-require-immutability 자세한 내용은 이 링크 참고
A shallow equality check is therefore as simple (and as fast) as a === b,
whereas a deep equality check involves a recursive traversal through the properties of two objects,
comparing the value of each property at each step.
It's for this improvement in performance that Redux uses shallow equality checking.덩치가 큰 객체를 비교해야 되는 상황이면 객체의 주소 비교라면 O(1) 만큼 비교를 하면 되지만, 속성을 비교하게 된다면 O(n)만큼 비교를 해야되기 때문에 시간이 오래 걸리므로 이러한 점때문에 성능상 이점을 얻기위해 구현된것 같았다.
Redux와 Flux
https://redux.js.org/understanding/history-and-design/prior-art 이 부분에는 다양한 기술들과 패턴이 redux에는 혼합되어있다고 한다고 하는데 그중 flux부분만 발췌해 보았다.
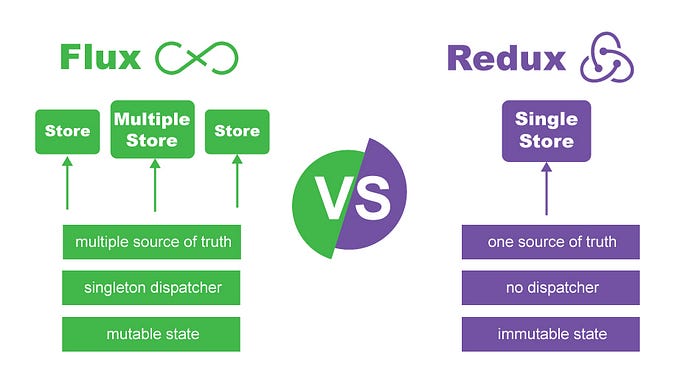 https://medium.com/@dakota.lillie/flux-vs-redux-a-comparison-bbd5000d5111 참고
https://medium.com/@dakota.lillie/flux-vs-redux-a-comparison-bbd5000d5111 참고
flux
같은점
flux와 같이 리덕스는 특정레이어에 모델 업데이트 로직을 집중시켜주게 해주었다고 하였고, flux에서는 store에, redux에서는 reducer에 라고하였다.
다른점
첫번쨰로는 flux와 다르게 리덕스는 dispatcher의 컨셉을 가지고 있지 않다고 설명이 나와있었다. 어렴풋하게는 액션을 디스패치 해주는 동작이 있으니 dispatcher의 컨셉을 가지고 있는게 아닌가 잠깐 생각했는데 여기서말하는 dispatcher는 flux의 멘탈모델 (Action, Dispatcher, Store, View)중 하나를 말한다
즉, dispatcher는 flux의 한 컨셉이고 액션디스패치는 flux, redux에서 발생하는 행위자체이며 이러한 액션 디스패치 행위를 통해 flux에서는 dispatcher로 등록된 콜백이 실행되어 store를 업데이트 하는 동작을 하게 되고, redux에서는 reducer로 액션을 전달해 관련 작업을 수행해 store로 업데이트 해주는 정도의 이후 흐름의 차이가 있다는 말이다. 헷갈릴수 있는 개념들이 한번 정리가 되었다.
flux에서의 dispatcher에 대해 추가적으로 말하자면 Flux 어플리케이션의 중앙 허브로 모든 데이터의 흐름을 관리한다.본질적으로 store의 콜백을 등록하는데 쓰이고 action creator가 새로운 action이 있다고 dispatcher에게 알려주면 어플리케이션에 있는 모든 store는 해당 action을 앞서 등록한 callback으로 전달 받는다고 한다.
또한 redux는 이러한 역할을 해주는 dispatcher대신 순수함수 성격을 띄는 reducer라는 스토어를 업데이하는 로직을 같은 성격의 하나의 레이어로 분리하고 쉽게 간결화하기도하며 쉽게 합치기도 한것 같다는 생각이 들었다.

또한 두번쨰로는 flux와 다르게 redux는 기존 data를 변경시키는 식으로 업데이트를 하지 않는것이다. 이는 항상 reducer에서 새로운 object 반환하는것과 같은 맥락이다. 앞서 말했듯 이러한 점때문에 redux에서 debugging역시 쉬워졌고, 빠른 데이터 비교가 가능해진것이다.



